Earlier this year, JumpWire had the opportunity to sponsor Shmoocon. Ryan and I have been frequent attendees of Shmoocon, it’s always been one of our favorite conferences to go to.
 |
|---|
| Our booth, complete with custom LEGO sign |
As a sponsor there’s an expectation that you’ll enhance the conference experience in some way - just showing up and trying to sell your product is lame and lazy. So like all good ~masochistic~ overly optimistic engineers, we decided the best thing to do would be to run a live CTF competition.

This post is mainly documentation of the infrastructure and setup needed for our challenges, but not a detailed explanation of the challenges themselves. We’ve also pushed up a public repo with all of the challenge code, explanations, and setup scripts in case you want to try running them yourself. You can find the repo at https://github.com/jumpwire-ai/shmoocon-ctf-2023
The Scoreboard - CTFd
There are two components for running a CTF: the challenge infrastucture, and the scoreboard. There are a few different options out there for scoreboard software, both commercial and FOSS. After looking at a few, I opted to run an instance of CTFd. It was really easy to work with when testing things locally and supported all of the features we needed for scoring. Most importantly, it has a CLI!
The sister project ctfcli creates/updates challenges from a local YAML definition. I’m allergic to mice so being able to just run a sync command as I deployed challenges was fantastic. It also gave us a standardized format for defining the challenge metadata - descriptions, point value, unlock order, etc. While the CLI isn’t necessary for that it was one less thing to think about.
For hosting the CTFd server, I setup some basic AWS resources:
- A VPC with a couple of subnets
- 1x EC2 instance (t4g.medium because ARM)
- An RDS instance for the CTFd DB (db.t3.medium with 10GB of storage)
- An ALB terminating SSL and forwarding HTTP traffic to the EC2 instance
- All the glue needed to make those services work - IAM policies and security groups and DNS records and LB targets and …
And of course, this and all other infrastructure definitions are encoded in Terraform because we live in a society and infrastructure is code.
Challenge hosting
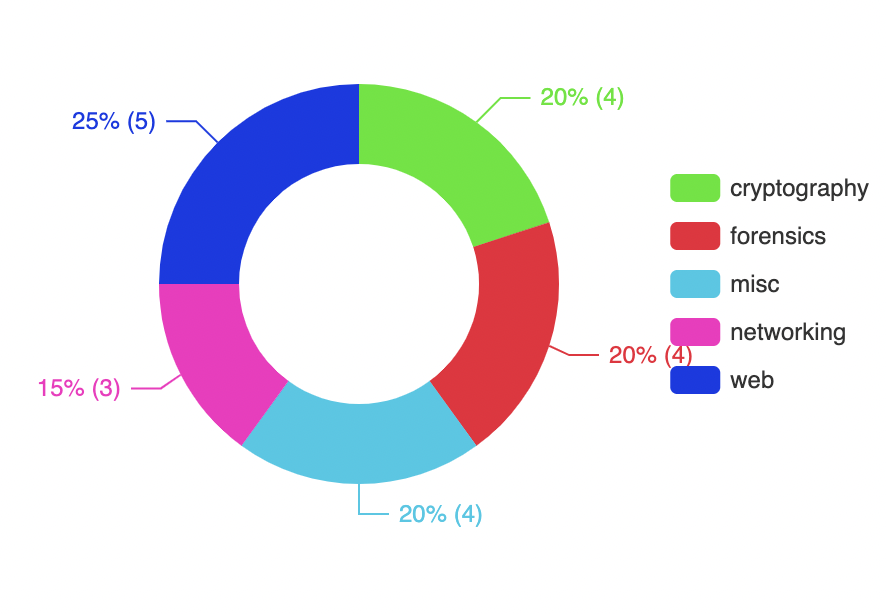 |
|---|
| Breakdown of challenge categories |
For a small amount of challenges we could upload a file for people to poke at. Most of the crypto challenges involved just a text blob, and we also had some basic forensic files: a git repo, Docker image, PCAP file, etc. These are all really easy to host. They got pushed up to AWS S3 by the ctfcli, and then a signed URL is generated in the scoreboard when someone views a challenge requiring them to download that file.
The rest of challenges mostly fell into the category of “connect to a port and Do Something Bad™️”. That meant I had to think about things a bit differently than a normal application. I needed to make sure that each service was going to be able to be reachable over the internet, to anonymous users, who are largely assumed to be at least semi-malicious. Many typical security layers are useless because I can expect people to get root on the service - in some cases, I explicitly want them to. At the same time, I want to keep costs as low as possible and I don’t want any operational burdon during the actual event.
Well, containers are great for binpacking a bunch of services together. With minimized kernel capabilities they even work pretty well as a security barrier. One option would be to spin up a container on a new TCP connection and burn it down afterwards. That’s nice in a lot of ways, but it’s too slow for our purposes. Serverless platforms like AWS Lambda would let us do essentially the same thing much faster - but then we lose the ability to have a full filesystem and OS behind the application, which we need for some of the challenges.
Docker with nsjail
After some academic research (eg web searches) I found a neat tool from Google called nsjail. Nsjail is intended to be run as the entrypoint for a network request to spawn and isolate a new process, closing out the process when the connection terminates. That’s exactly what I want! Running nsjail inside a Docker container lets me deploy to a cloud provider to host the challenges very cheaply and easily, while still giving process isolation between tenants.

Not every challenge needed this setup. The simplest ones, such as serving a static HTML page, had no real vectors to break into the container, so nsjail would be overkill. But for the challenges that needed the extra isolation nsjail worked beautifully.
AWS isolation
Along the same vein, I created a set of challenges based on AWS resources. This was particularly tricky for the same reason - I didn’t want people to stomp on each others toes, intentionally or accidentally. I had to keep the scope to things that I could isolate further than what AWS provides, or read-only access to shared resources. As an illustrative example, I partially designed one challenge to involve launching a new EC2 instance with a specific IAM profile attached, but I worried about granting that level of permissions. Instead the challenge ended up using a static EC2 instance with hidden SSH credentials. When connected to, sshd on that instance used our favorite little buddy - nsjail - to spawn an isolated shell. The shell gets terminated as soon as the connection closes and any temp files get cleaned up.
Each challenge was also isolated in its own subaccount, reducing the likelihood of cross-account contamination. It also makes it easy to clean up everything after the competition - just delete the whole subaccount!
Deploy to fly.io
To host our Docker-based challenges I setup a new project in fly.io. Fly is a very nice deployment platform, similar in spirit to Heroku before they killed their free tier. Since the requirements were basically “run Docker, expose a port, put a TLS cert in front of it”, we could have used any number of platforms. Fly had the dual benefit of being really cheap for tiny runtimes and really simple to deploy to.
The TLS handling in particular was a big time save - Fly can setup ACME DNS validation for you, so it becomes as easy as point a DNS CNAME record at the Fly app and tell Fly to generate a new cert. I wrapped up this logic in a terraform module to make it reusable:
variable "name" {
type = string
}
locals {
fly_app = "ctf-${var.name}"
hostname = "${var.name}.ctf"
}
data "cloudflare_zone" "jumpwire_ai" {
name = "jumpwire.ai"
}
data "fly_app" "app" {
name = local.fly_app
}
resource "fly_cert" "app" {
app = data.fly_app.app.id
hostname = "${local.hostname}.jumpwire.ai"
}
resource "cloudflare_record" "fly_app" {
zone_id = data.cloudflare_zone.jumpwire_ai.id
name = local.hostname
value = "${data.fly_app.app.id}.fly.dev"
type = "CNAME"
ttl = 3600
proxied = false
}And then just called that module with a list of challenges:
variable "challenges" {
type = set(string)
default = [
"jwt",
"wiki",
"blog",
"penguin",
"self-reflection",
"green-thumb",
"pwn",
"cannaregio",
"bot-script",
]
}
module "challenges" {
for_each = var.challenges
source = "./modules/challenge"
name = each.value
}Serverless
To keep in the theme of “I don’t want to manage infrastructure in the middle of a live competition at a conference”, I also mixed in a few serverless tools. One challenge in particular used a GraphQL API to call a PostgreSQL database. The main part of this challenge was deployed as a Docker container in fly as described above, but I used Hasura for handling the GraphQL API. Hasura made it really easy to just point to a DB, pull out the schema, create a GraphQL backend for it, and enforce some (intentionally broken) permissions on the calls.
While setting up Hasura I also tried out neon.tech - a pretty new serverless PostgreSQL provider. At the time they only had very light demo/beta plans available, which is all I needed for running this challenge. I expected some pains but didn’t really hit any - it took just a few minutes to go from “never heard of this product” to “deployed DB with my schema and roles setup.” I’m definitely looking forward to using neon.tech more in the future!
WiFi
One final piece of infrastructure worth calling out is the hardware we used for hosting a set of WiFi challenges. The intent here was to sniff some traffic near out booth, then connect and progress deeper into the network. This mostly worked, although we ran into some issues described below. It was also the most involved setup of any of our challenges - probably because I was intent on reusing hardware I had laying around instead of buying anything new.
Our network consisted of two physical nodes, an old laptop and phone. The phone was configured to connect to a hidden 802.11n network hosted by the laptop, and that’s about where the configuration of the phone ended.
The laptop itself was using hostapd and dnsmasq to act as an AP and router for connecting clients. I setup a dummy interface with its own subnet, with clients able to route into anything on that subnet once connected using iptables rules. This basically gave me a full network to play with and run services on without having to actually setup a bunch of hardware.
Given time constraints, I only ended up creating two other services on this network - a captive portal, and a vulnerable service on the internal network visible after bypassing the portal. Both were running in Docker to make them appear as independant network hosts, although the portal being run by opennds needed some elevated capabilities - NET_ADMIN and NET_RAW.
Live event
Just like live demos, you can’t run a real a live event without some issues and we were no exception. We got our booth setup (complete with our awesome LEGO logo sign) and started telling people about the CTF. To try to make things a bit fairer we had scheduled the CTF registrations to open later in the afternoon. Once the competition started it was only a few minutes until our first solve, ironically from a team named simply 1.
We kept a vague eye on the scoreboard from our booth and after a while noticed some challenges that we thought of as being easier weren’t being solved. In particular, a XSS challenge was surprising us as being completely unsolved. Coincidentally, that challege uses some heavyweight headless Chrome processes that were poorly (never?) cleaned up. That process was too underpowered to handle the massive volume of over two dozen concurrent requests (/s) - so we did what any good infrastructure team would do and threw more resources at it. Problem solved!
The other major issue we ran into was around our WiFi challenges. They were designed to be serialized and you needed to be in close proximity to our booth in order to see the traffic. Unbeknownst to us when designing the challenges, there was an entire radio wave CTF happening right next to our booth. This MAY have caused some issues with our WiFi setup, but whatever the cause we definitely had issues with people not seeing our traffic. At the end of Friday we packed everything up, and then recreated the setup fresh on Saturday. Now it started working - four teams solved at least the first WiFi challenge on Saturday. Same configuration, same hardware, same location ¯\(ツ)/¯
Other than that, things went pretty smoothly. It was very rewarding seeing so many smart people try to puzzle their way through the challenges after spending so much time making them.
Statistics
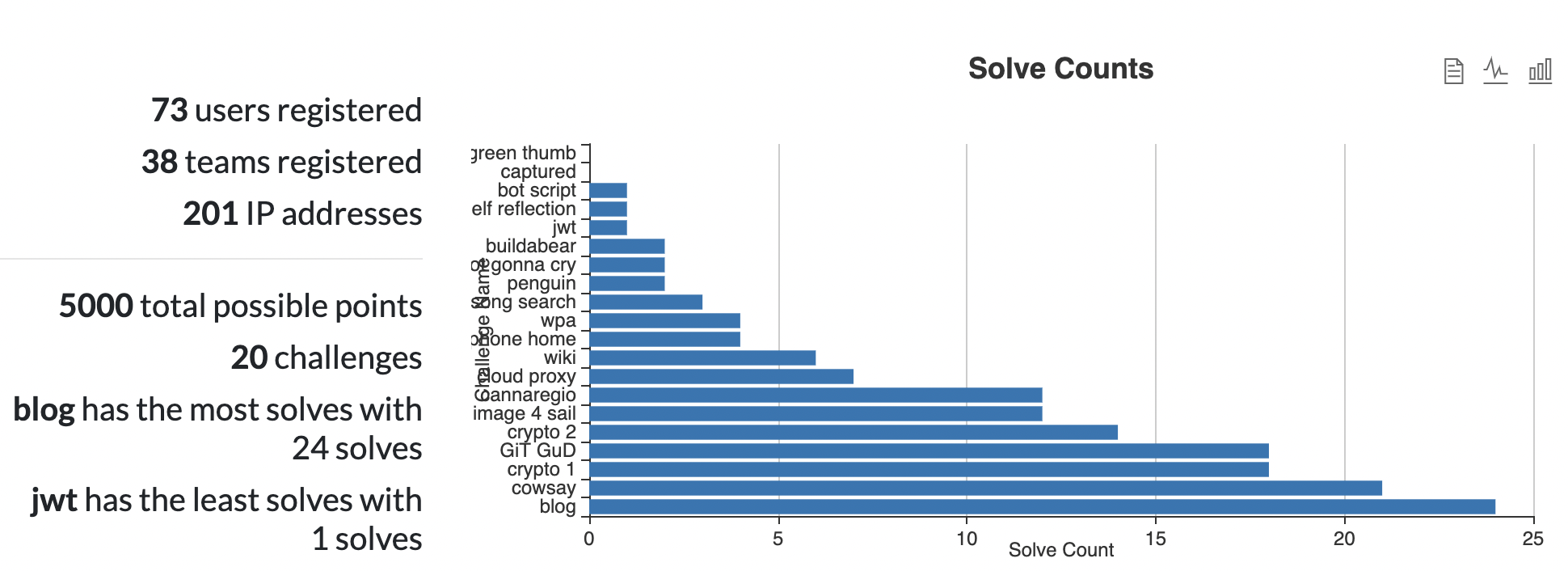
Some interesting numbers from our CTF:
We had 74 users register across 39 different teams.
Our most solved challenge was solved 24 times.
3 challenges were solved only once, and 2 challenges were never solved.
There were a total of 5000 possible points for solving all challenges.
The highest score was 3150, and there was a long tail of teams scoring 750+ points.
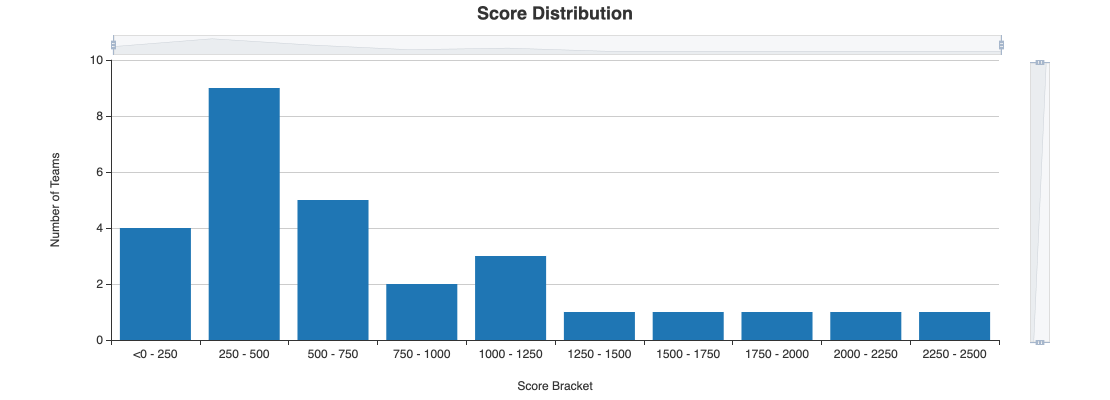
The winning team, makeinstall, was the only team that solved our two harder web challenges. Makeinstall was also a team consisting of a single person.
The top three spots were a tight battle that ran to the last few minutes of the event
Summary
So what are the lessons here?
1) If it doesn’t work, turn it off and on again
2) If it’s crashing throw more CPU and RAM at it
3) Hope is a great strategy when it comes to monitoring a live event
Overall, even though planning the CTF was a ton more work than expected, it was really fun and we hope to run another one at a future conference. We’ll make sure to post any upcoming event plans on this blog and our newsletter.
- William